PhotoMaker
Bringing a person in artwork/old photo into reality.Let us create photos/paintings/avatars for anyone in any style within seconds.
标签:AI Art GeneratorsPhoto MakerWhat is PhotoMaker
Users can input one or a few face photos, along with a text prompt, to receive a customized photo or painting within seconds.Customizing Realistic Human Photos via Stacked ID Embedding
Personalization steps:
- Upload images of someone you want to customize. One image is ok, but more is better. Although we do not perform face detection, the face in the uploaded image should occupy the majority of the image.
- Enter a text prompt, making sure to follow the class word you want to customize with the trigger word:
img, such as:man imgorwoman imgorgirl img. - Choose your preferred style template.
- Click the Submit button to start customizing.
Latest Examples
Realistic photos
Select to browse the personalization results. The first row is the reference ID image.

Stylization
Select to browse the personalization results. The first row is the reference ID image.

Abstract
Recent advances in text-to-image generation have made remarkable progress in synthesizing realistic human photos conditioned on given text prompts. However, existing personalized generation methods cannot simultaneously satisfy the requirements of high efficiency, promising identity (ID) fidelity, and flexible text controllability. In this work, we introduce PhotoMaker, an efficient personalized text-to-image generation method, which mainly encodes an arbitrary number of input ID images into a stack ID embedding for preserving ID information. Such an embedding, serving as a unified ID representation, can not only encapsulate the characteristics of the same input ID comprehensively, but also accommodate the characteristics of different IDs for subsequent integration. This paves the way for more intriguing and practically valuable applications. Besides, to drive the training of our PhotoMaker, we propose an ID-oriented data construction pipeline to assemble the training data. Under the nourishment of the dataset constructed through the proposed pipeline, our PhotoMaker demonstrates better ID preservation ability than test-time fine-tuning based methods, yet provides significant speed improvements, high-quality generation results, strong generalization capabilities, and a wide range of applications.
Method
Our method transforms a few input images of the same identity into a stacked ID embedding. This embedding can be regarded as a unified representation of the ID to be generated. During the inference stage, the images constituting the stacked ID embedding can originate from different IDs. We then can synthesize the customized ID in difference contexts.
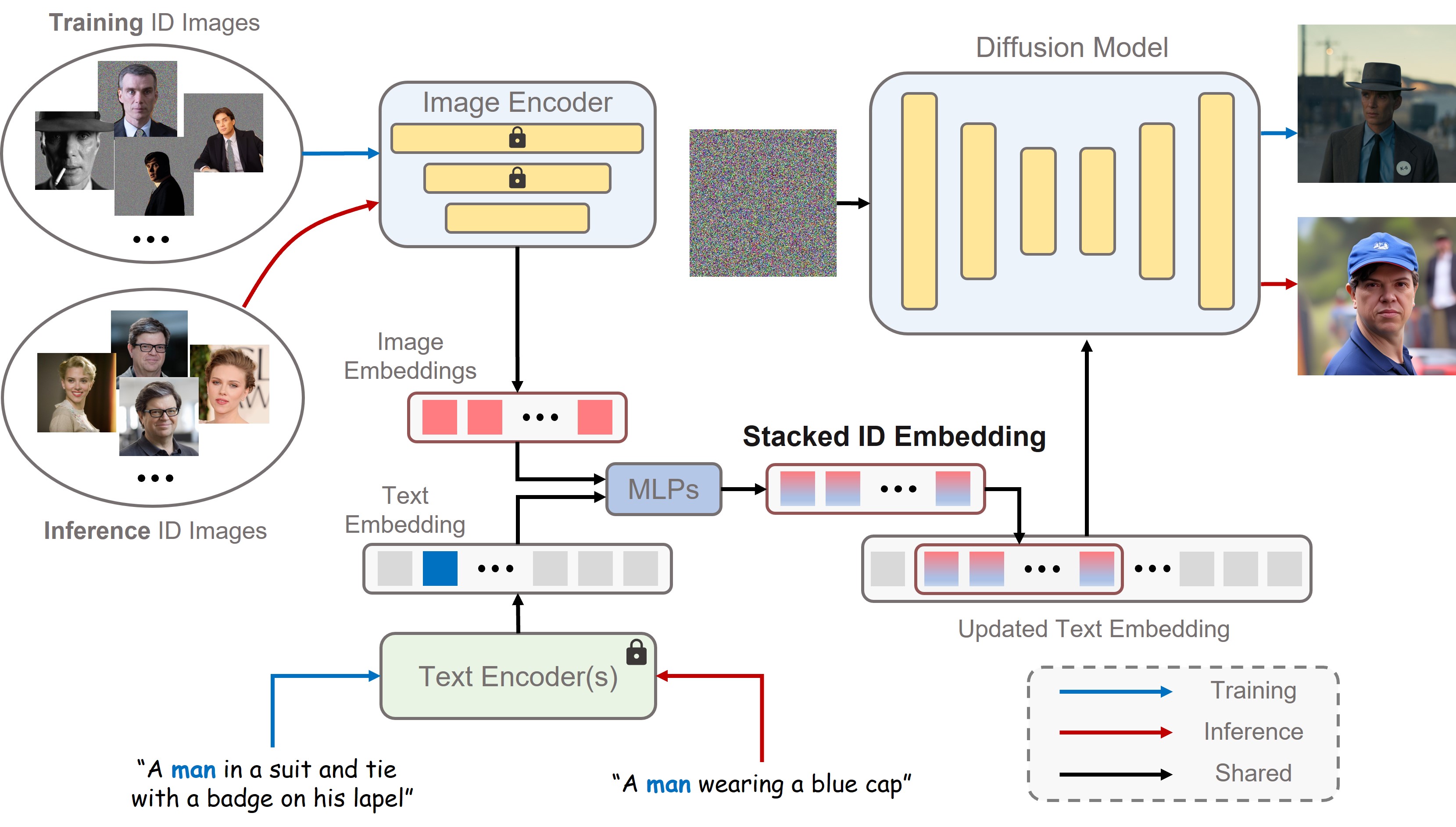
We first obtain the text embedding and image embeddings from text encoder(s) and image encoder, respectively. Then, we extract the fused embedding by merging the corresponding class embedding (e.g., man and woman) and each image embedding. Next, we concatenate all fused embeddings along the length dimension to form the stacked ID embedding. Finally, we feed the stacked ID embedding to all cross-attention layers for adaptively merging the ID content in the diffusion model. Note that although we use images of the same ID with the masked background during training, we can directly input images of different IDs without background distortion to create a new ID during inference.