DreaMoving Reviews:A Human Dance Video Generation Framework based on Diffusion Models
About DreaMoving
A Human Dance Video Generation Framework based on Diffusion Models
Abstract
In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human dance videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving.
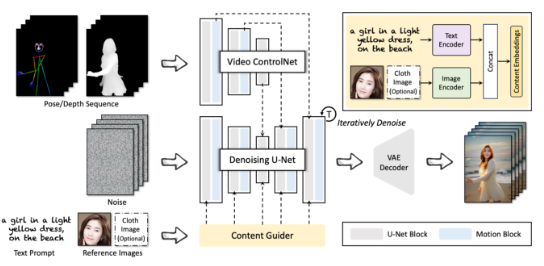
Architecture
The overview of DreaMoving. The Video ControlNet is the image ControlNet injected with motion blocks after each U-Net block. The Video ControlNet processes the control sequence (pose or depth) to additional temporal residuals. The Denoising U-Net is a derived Stable-Diffusion U-Net with motion blocks for video generation. The Content Guider transfers the input text prompts and appearance expressions, such as the human face (the cloth is optional), to content embeddings for cross attention.
Results
DreaMoving can generate high-quality and high-fidelity videos given guidance sequence and simple content description, e.g., text and reference image, as input. Specifically, DreaMoving demonstrates proficiency in identity control through a face reference image, precise motion manipulation via a pose sequence, and comprehensive video appearance control prompted by a specified text prompt.

Unseen domain results
DreaMoving exhibits robust generalization capabilities on unseen domains.

Citation
@article{feng2023dreamoving, title={DreaMoving: A Human Video Generation Framework based on Diffusion Models}, author={Mengyang Feng, Jinlin Liu, Kai Yu, Yuan Yao, Zheng Hui, Xiefan Guo, Xianhui Lin, Haolan Xue, Chen Shi, Xiaowen Li, Aojie Li, Xiaoyang Kang, Biwen Lei, Miaomiao Cui, Peiran Ren, Xuansong Xie}, journal={arXiv}, year={2023}}

