IP-Adapter-FaceID Model Card
An experimental version of IP-Adapter-FaceID: we use face ID embedding from a face recognition model instead of CLIP image embedding, additionally, we use LoRA to improve ID consistency. IP-Adapter-FaceID can generate various style images conditioned on a face with only text prompts.

Update 2023/12/27:
IP-Adapter-FaceID-Plus: face ID embedding (for face ID) + CLIP image embedding (for face structure)

Update 2023/12/28:
IP-Adapter-FaceID-PlusV2: face ID embedding (for face ID) + controllable CLIP image embedding (for face structure)
You can adjust the weight of the face structure to get different generation!

Usage
IP-Adapter-FaceID
Firstly, you should use insightface to extract face ID embedding:
import cv2
from insightface.app import FaceAnalysis
import torch
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.imread("person.jpg")
faces = app.get(image)
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
Then, you can generate images conditioned on the face embeddings:
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler, AutoencoderKL
from PIL import Image
from ip_adapter.ip_adapter_faceid import IPAdapterFaceID
base_model_path = "SG161222/Realistic_Vision_V4.0_noVAE"
vae_model_path = "stabilityai/sd-vae-ft-mse"
ip_ckpt = "ip-adapter-faceid_sd15.bin"
device = "cuda"
noise_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
vae = AutoencoderKL.from_pretrained(vae_model_path).to(dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
scheduler=noise_scheduler,
vae=vae,
feature_extractor=None,
safety_checker=None
)
# load ip-adapter
ip_model = IPAdapterFaceID(pipe, ip_ckpt, device)
# generate image
prompt = "photo of a woman in red dress in a garden"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality, blurry"
images = ip_model.generate(
prompt=prompt, negative_prompt=negative_prompt, faceid_embeds=faceid_embeds, num_samples=4, width=512, height=768, num_inference_steps=30, seed=2023
)
IP-Adapter-FaceID-Plus
Firstly, you should use insightface to extract face ID embedding and face image:
import cv2
from insightface.app import FaceAnalysis
from insightface.utils import face_align
import torch
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.imread("person.jpg")
faces = app.get(image)
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
face_image = face_align.norm_crop(image, landmark=faces[0].kps, image_size=224) # you can also segment the face
Then, you can generate images conditioned on the face embeddings:
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler, AutoencoderKL
from PIL import Image
from ip_adapter.ip_adapter_faceid import IPAdapterFaceIDPlus
v2 = False
base_model_path = "SG161222/Realistic_Vision_V4.0_noVAE"
vae_model_path = "stabilityai/sd-vae-ft-mse"
image_encoder_path = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
ip_ckpt = "ip-adapter-faceid-plus_sd15.bin" if not v2 else "ip-adapter-faceid-plusv2_sd15.bin"
device = "cuda"
noise_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
vae = AutoencoderKL.from_pretrained(vae_model_path).to(dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
scheduler=noise_scheduler,
vae=vae,
feature_extractor=None,
safety_checker=None
)
# load ip-adapter
ip_model = IPAdapterFaceIDPlus(pipe, image_encoder_path, ip_ckpt, device)
# generate image
prompt = "photo of a woman in red dress in a garden"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality, blurry"
images = ip_model.generate(
prompt=prompt, negative_prompt=negative_prompt, face_image=face_image, faceid_embeds=faceid_embeds, shortcut=v2, s_scale=1.0,
num_samples=4, width=512, height=768, num_inference_steps=30, seed=2023
)
Limitations and Bias
- The model does not achieve perfect photorealism and ID consistency.
- The generalization of the model is limited due to limitations of the training data, base model and face recognition model.
Non-commercial use
This model is released exclusively for research purposes and is not intended for commercial use.
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Tencent AI Lab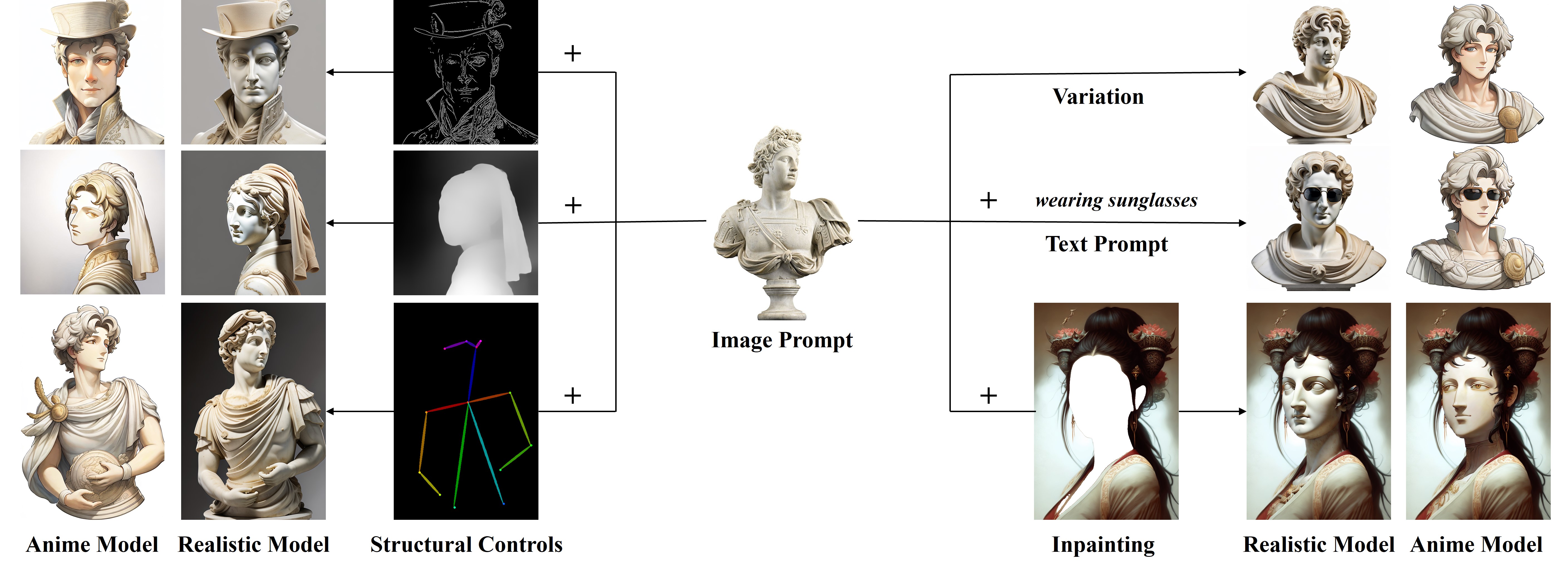
Various image synthesis with our proposed IP-Adapter applied on the pretrained text-to-image diffusion model and additional structure controller.
Abstract
Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. But, it is very tricky to generate desired images using only text prompt as it often involves complex prompt engineering. An alternative to text prompt is image prompt, as the saying goes: “an image is worth a thousand words”. Although existing methods of direct fine-tuning from pretrained models are effective, they require large computing resources and are not compatible with other base models, text prompt, and structural controls. In this paper, we present IP-Adapter, an effective and lightweight adapter to achieve image prompt capability for the pretrained text-to-image diffusion models. The key design of our IP-Adapter is decoupled cross-attention mechanism that separates cross-attention layers for text features and image features. Despite the simplicity of our method, an IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fine-tuned image prompt model. As we freeze the pretrained duffusion model, the proposed IP-Adapter can be generalized not only to other custom models fine-tuned from the same base model, but also to controllable generation using existing controllable tools. With the benefit of the decoupled cross-attention strategy, the image prompt can also work well with the text prompt to accomplish multimodal image generation.
Approach
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate images with image prompt. The proposed IP-Adapter consists of two parts: a image encoder to extract image features from image prompt, and adapted modules with decoupled cross-attention to embed image features into the pretrained text-to-image diffusion model.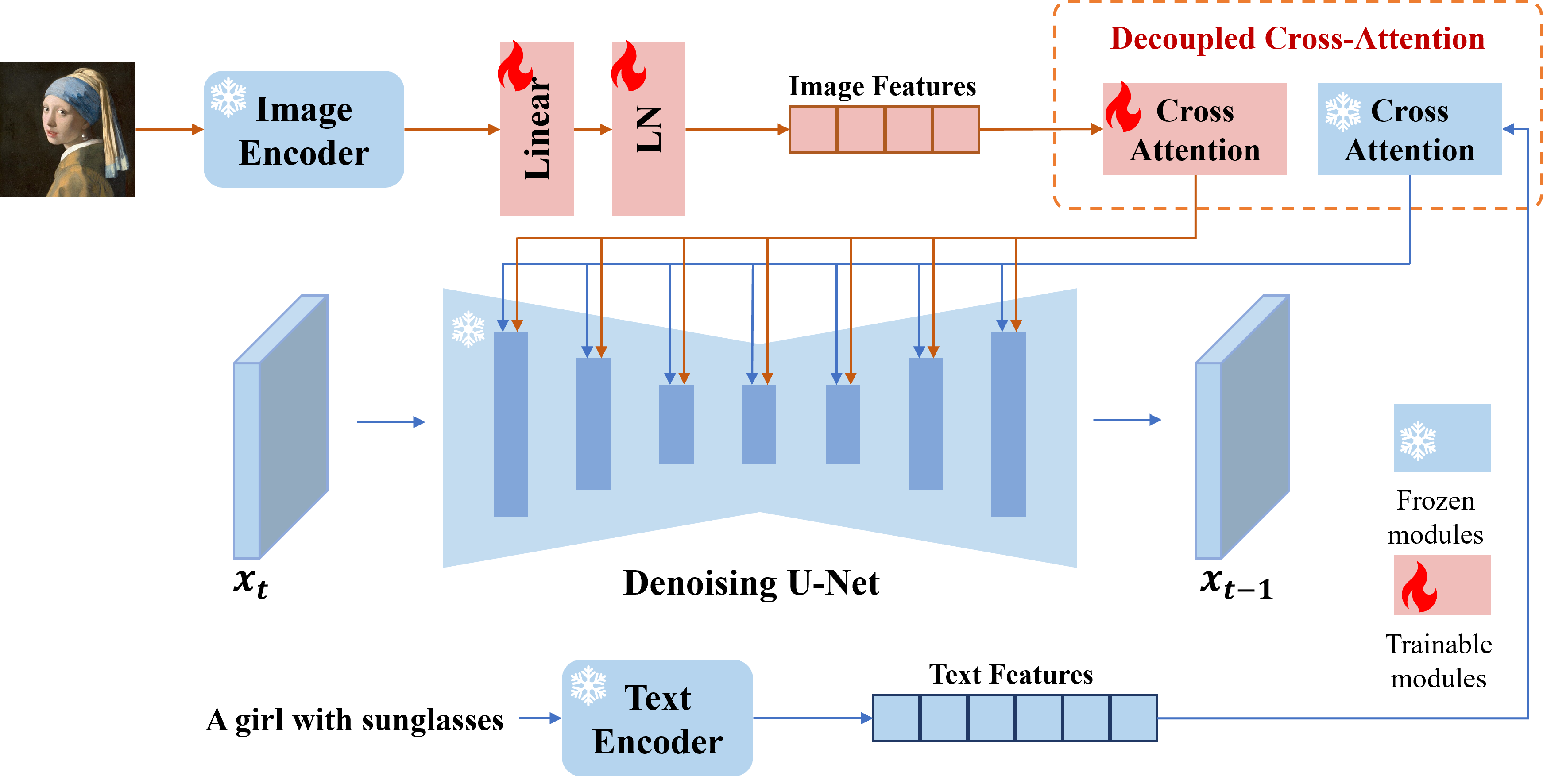
Comparison with Existing Methods
The comparison of our proposed IP-Adapter with other methods conditioned on different kinds and styles of images.
More Results
Generalizable to Custom Models
Once the IP-Adapter is trained, it can be directly reusable on custom models fine-tuned from the same base model.
Structure Control
The IP-Adapter is fully compatible with existing controllable tools, e.g., ControlNet and T2I-Adapter.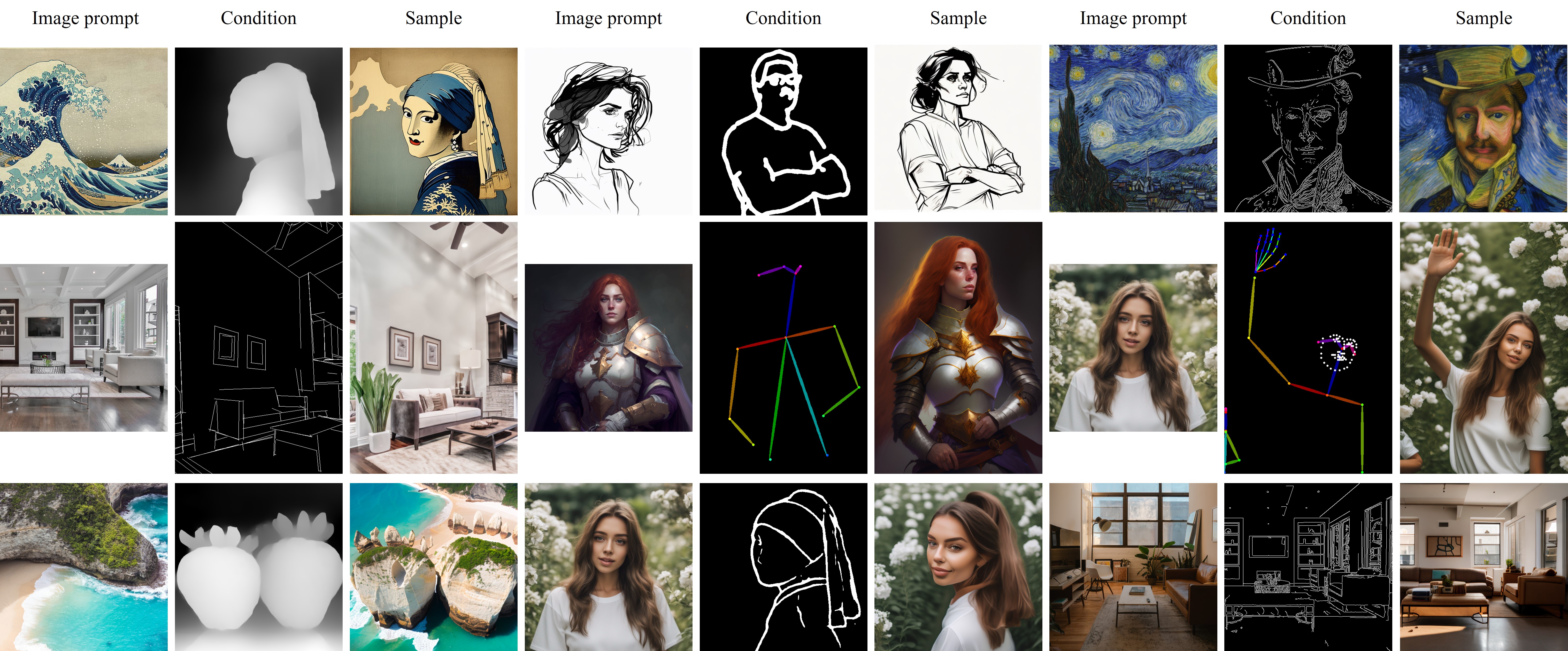
Our method not only outperforms other methods in terms of image quality, but also produces images that better align with the reference image.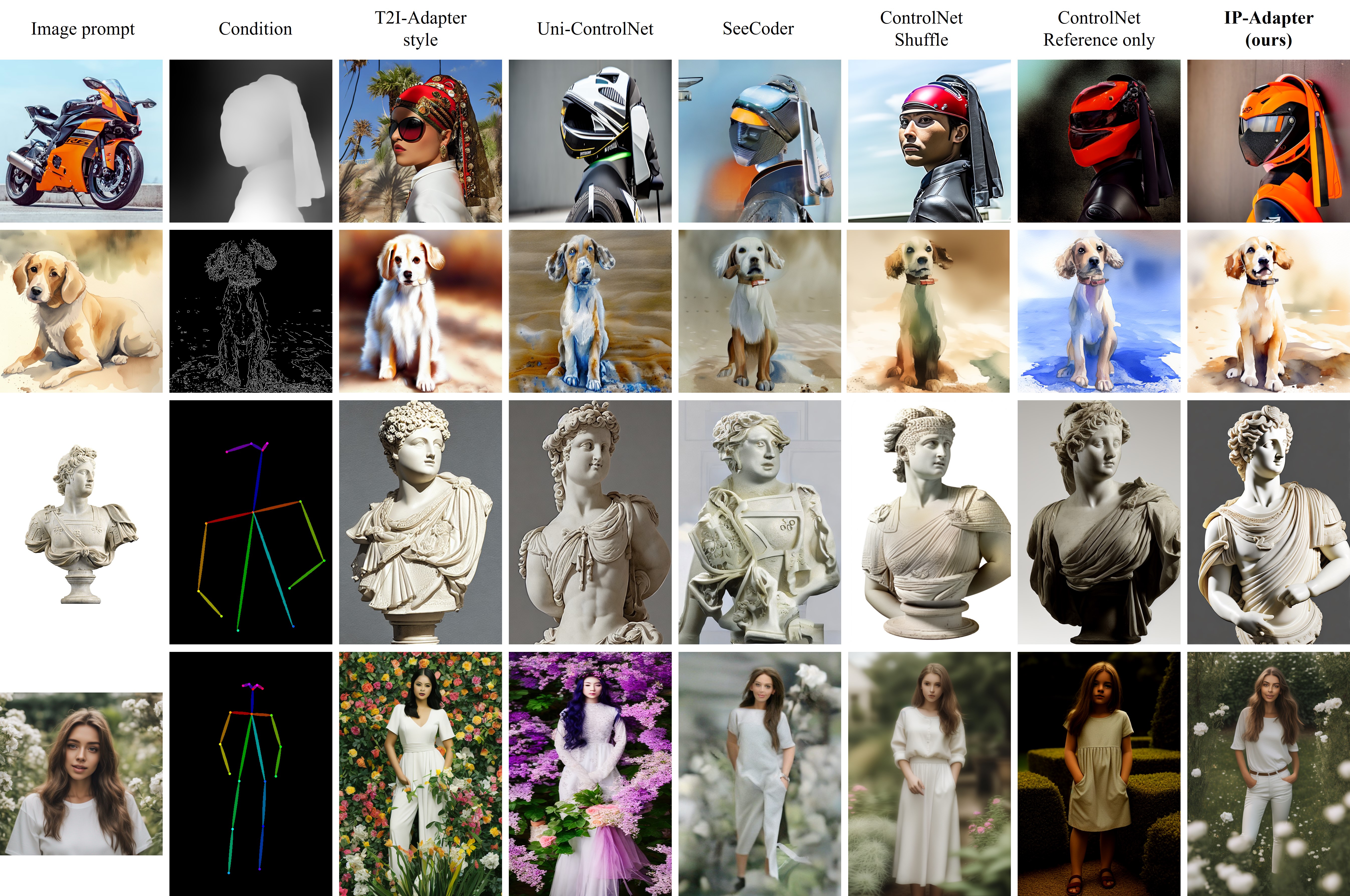
Image-to-Image and Inpainting
Image-guided image-to-image and inpainting can be also achieved by simply replacing text prompt with image prompt.
Multimodal Prompt
Due to the decoupled cross-attention strategy, image prompt can work together with text prompt to realize multimodal image generation.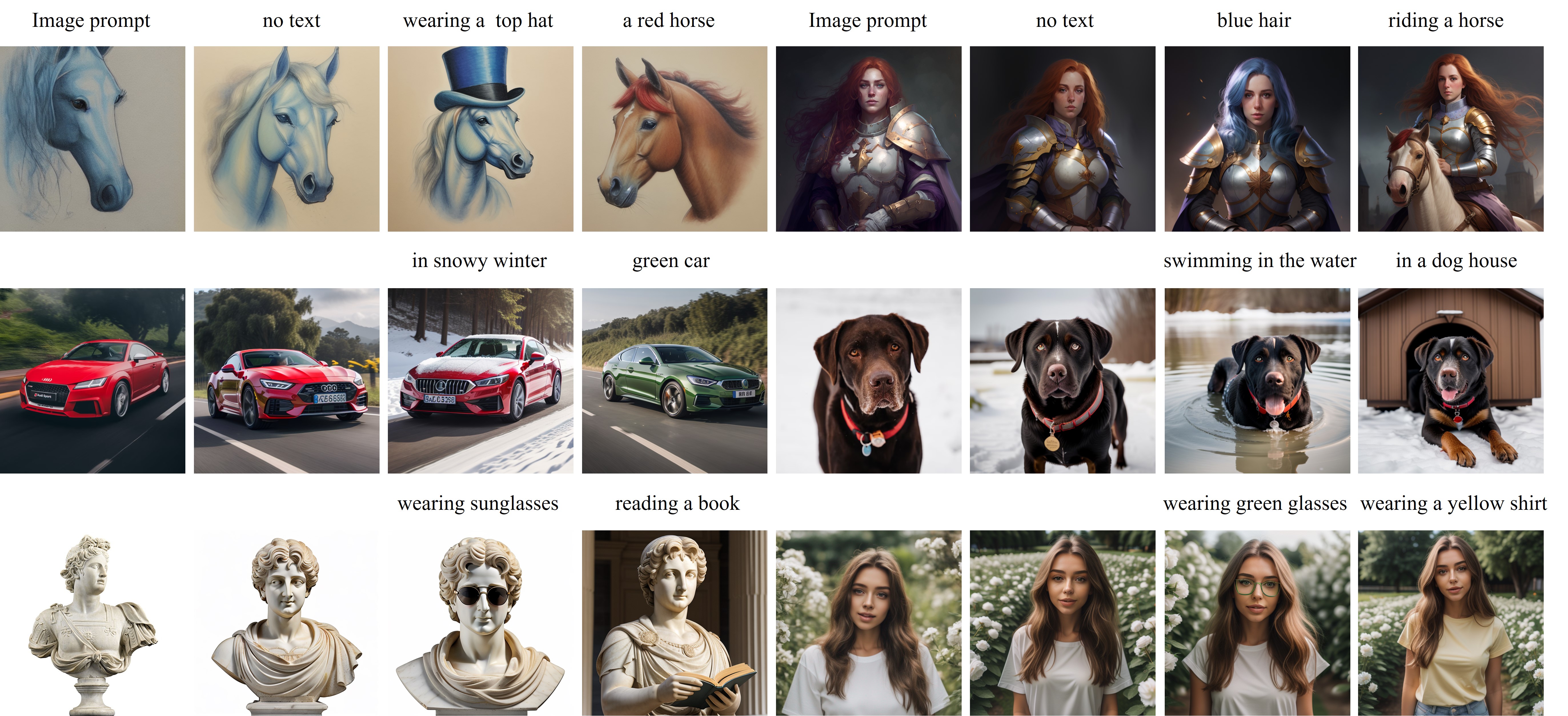
Compared with other existing methods, our method can generate superior results in both image quality and alignment with multimodal prompts.
BibTex
@article{ye2023ip-adapter,
title={IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models},
author={Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei},
booktitle={arXiv preprint arxiv:2308.06721},
year={2023}
}

