WizardLM Reviews:Empowering Large Pre-Trained Language Models to Follow Complex Instructions
About WizardLM
WizardLM is a family of large language models that have been trained to follow complex instructions across domains like general conversation, coding, and math. The models use a novel training method called Evol-Instruct to automatically generate challenging instructions to improve performance. Key features of WizardLM models include multi-turn conversation, high accuracy on tasks like HumanEval, and mathematical reasoning compared to other open source models.
The GitHub repo provides model checkpoints, demos, and documentation for WizardLM, WizardCoder, and WizardMath models – ranging from 1B to 70B parameters.
What is wizard coder?
In this paper, we introduce WizardCoder, which empowers Code LLMs with complex instruction fine-tuning, by adapting the Evol-Instruct method to the domain of code.
WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
WizardCoder
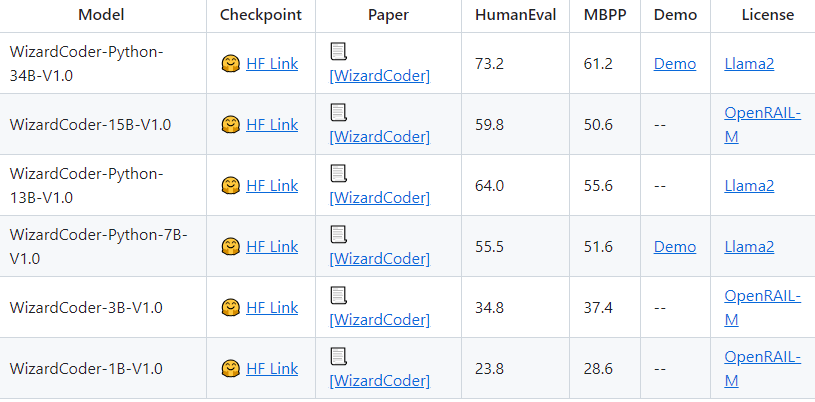
We released WizardCoder-Python-34B-V1.0 , which achieves the 73.2 pass@1 and surpasses GPT4 (2023/03/15), ChatGPT-3.5, and Claude2 on the HumanEval Benchmarks. For more details, please refer to WizardCoder.
WizardMath
Our WizardMath-70B-V1.0 model slightly outperforms some closed-source LLMs on the GSM8K, including ChatGPT 3.5, Claude Instant 1 and PaLM 2 540B.

WizardLM
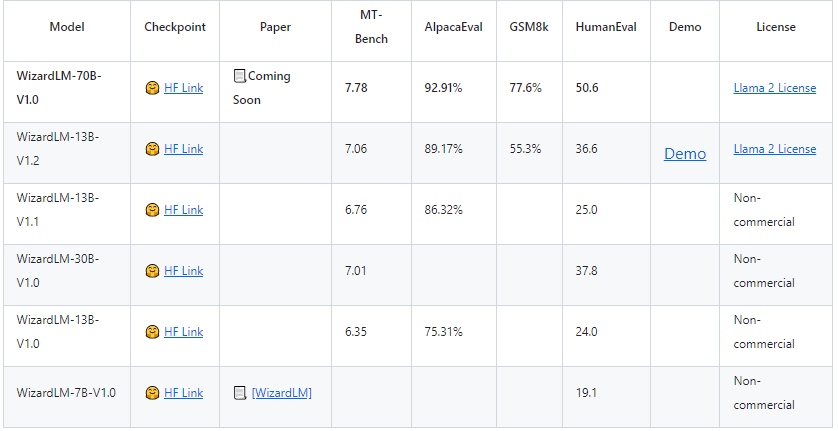
We released WizardLM-70B-V1.0 model.
GPT-4 automatic evaluation
We adopt the automatic evaluation framework based on GPT-4 proposed by FastChat to assess the performance of chatbot models. As shown in the following figure, WizardLM-30B achieved better results than Guanaco-65B.

WizardLM-30B performance on different skills.
The following figure compares WizardLM-30B and ChatGPT’s skill on Evol-Instruct testset. The result indicates that WizardLM-30B achieves 97.8% of ChatGPT’s performance on average, with almost 100% (or more than) capacity on 18 skills, and more than 90% capacity on 24 skills.

WizardLM performance on NLP foundation tasks.
The following table provides a comparison of WizardLMs and other LLMs on NLP foundation tasks. The results indicate that WizardLMs consistently exhibit superior performance in comparison to the LLaMa models of the same size. Furthermore, our WizardLM-30B model showcases comparable performance to OpenAI’s Text-davinci-003 on the MMLU and HellaSwag benchmarks.
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|---|---|---|---|---|---|
| Text-davinci-003 | 56.9 | 85.2 | 59.3 | 82.2 | 70.9 |
| Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
| Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-30B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2 |
WizardLM performance on code generation.
The following table provides a comprehensive comparison of WizardLMs and several other LLMs on the code generation task, namely HumanEval. The evaluation metric is pass@1. The results indicate that WizardLMs consistently exhibit superior performance in comparison to the LLaMa models of the same size. Furthermore, our WizardLM-30B model surpasses StarCoder and OpenAI’s code-cushman-001. Moreover, our Code LLM, WizardCoder, demonstrates exceptional performance, achieving a pass@1 score of 57.3, surpassing the open-source SOTA by approximately 20 points.
| Model | HumanEval Pass@1 |
|---|---|
| LLaMA-7B | 10.5 |
| LLaMA-13B | 15.8 |
| CodeGen-16B-Multi | 18.3 |
| CodeGeeX | 22.9 |
| LLaMA-33B | 21.7 |
| LLaMA-65B | 23.7 |
| PaLM-540B | 26.2 |
| CodeGen-16B-Mono | 29.3 |
| code-cushman-001 | 33.5 |
| StarCoder | 33.6 |
| WizardLM-7B 1.0 | 19.1 |
| WizardLM-13B 1.0 | 24.0 |
| WizardLM-30B 1.0 | 37.8 |
| WizardCoder-15B 1.0 | 57.3 |
Tools similar to WizardLM
Bing Chat
Langfuse
LlamaIndex
Stable Beluga 2

