Musci Gen 使用及安装翻译手册
今天,我看到一篇文章,介绍Music Gen,看了一下发现AI生成音乐确实强大,竟然是开源有GIT仓的,Fouquet博士还专门录制了一个视频,怎么介绍这个Music Gen,使用及安装的方法。现在我就放上GIT地址,和模型地址。对照视频,和翻译应该很容易玩起来。
开源地址:https://github.com/facebookresearch/audiocraft
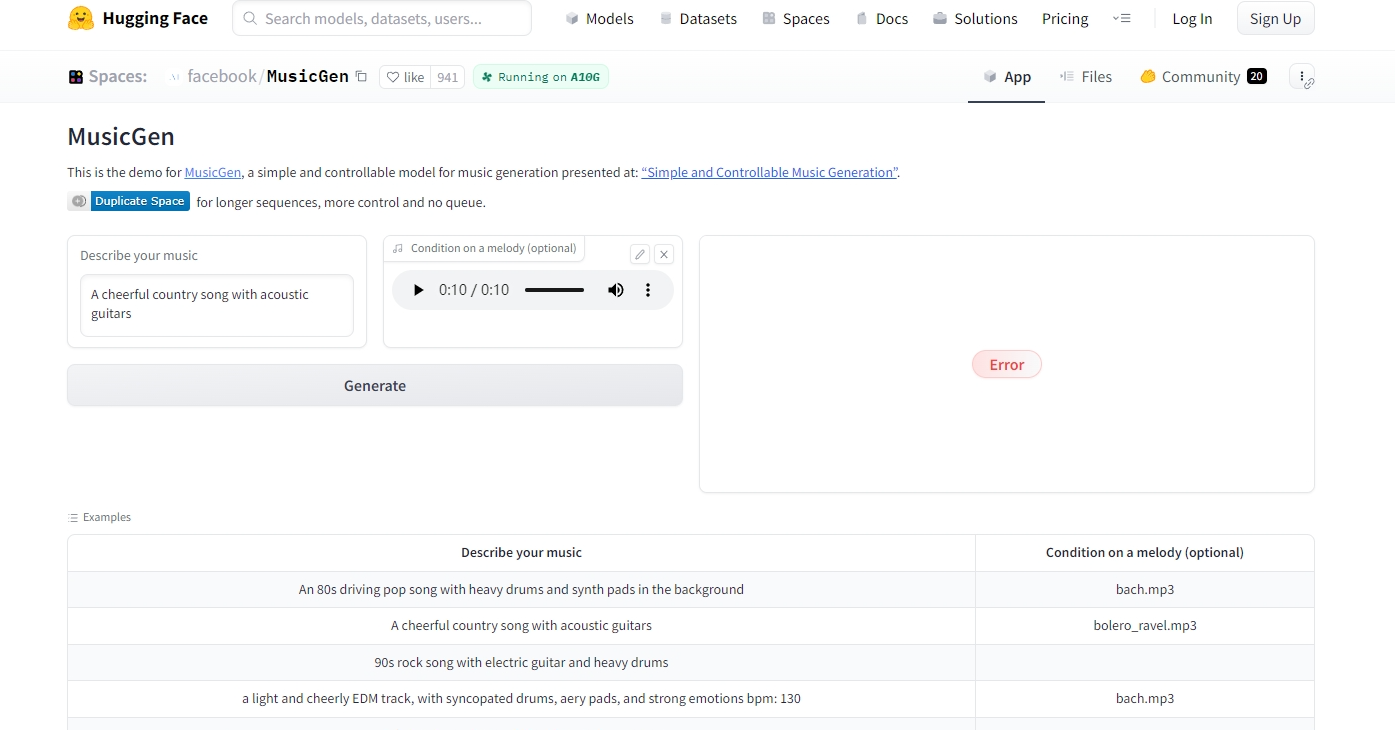
免费在线测试地址:https://huggingface.co/spaces/facebook/MusicGen
https://github.com/FurkanGozukara/Stable-Diffusion/blob/main/Tutorials/AI-Music-Generation-Audiocraft-Tutorial.md 安装步骤
Furuuen博士视频地址:
内容全英文:
00:00
Greetings, everyone. FaceBook research has released audio craft, which can generate music from text prompts or from given audio files. Audio Craft is the best ever release music generator so far today. I will show you how to install and use it. I will begin with showing you some of the samples I have generated on my computer. I am very bad at music, so you can consider these are the worst generated samples. Now listen them together.
01:02
For generating this song, I have used this input text, and I didn’t use any middle of the condition. I use it. The large model with default parameters, the large model works very well on RTX. 3090. Probably it requires about 15. 16 GB. We are memory. However, if you have lower viram having GPU, you can use media model or small model as well.
01:28
Degenerated music files are not saved on your computer by default. So you need to create this three. That’s icon here and click download. And it will save the generated audio file into your Domus boulders. It is totally up to you to how you prompt get your output. I didn’t have much chance to test yet to find better examples. But still, this model is amazing. Now, in this example, I am showing you the combination of this prompt with back MP3 file that comes along with the model itself. Let’s listen to generated music.
02:39
I also use the Discretive comments song as an example as well. Let me also show you, how does it sound, And it is amazing. So first, I will let you listen. The melody conditioning.
03:07
And now let’s listen to generated music with taking this melody condition and also this input text.
03:44
As I said. This is another cherry picking. This is the first time generation, because I didn’t have much time to test and do more experimentation. So for installation, I have prepared an amazing GitHub Redmi file. This file link will be description of the video. This file will get updated as it is necessary, so you may find more information on this file. Why I am using such files, because I am producing a lot of AI content and depositories gets updated all the time and gets broken all the time so quickly. So I will keep this file up to date, and you will be able to always follow this video and install and use this open source library.
04:29
So there are two requirements that you need to do. First, you need to install Python. I suggest you to use Python, three point x version. I am Python three point 10.9, and it should be set in the pad as a default. So when you type item in your next and the window, you should see a message like this. The second thing that you need to have installed is Git. When you type. Git in your C, MD window, You should see a gift message like this. If you don’t know how to install them, I have an excellent tutorial video. The link is here and the dome up links are in here.
05:08
So now I will show the installation of audio craft on your computer. I also have preparation, auto install and run cigarette, which is shared on my Patreon post. You can download these secrets and directly use them. I will also show how to use them as well. So we will have a comparison. I have put every command here 1 by one. So it is very easy to follow if you don’t want to use my automated secrets.
05:34
So first enter inside the folder where you want to install your, I will make test three folder like this. I have entered inside folder. First, we will begin with colonic repository here. So open a new C, MD, wiggle in here. And this is where my C, M.
05:52
D window is, right click and start cloning. Then move into the colonnade powder, copy it, paste it, and move it folder. Then if you want to use the same version that I have used in this video, do get checkout. Do this only if you encounter problems and if it doesn’t work. Otherwise, you don’t need to do this.
06:12
You should use the, it’s a version of the repository because developers usually fix bugs and add new features, then we will generate our own mutual. This is really important because with this way, it won’t conflict with your other installations. Such as stable division. Copy, paste. And his answer, then we will activate the virtual environment. This is really important. You need to always work with activated virtual environments.
06:41
Then we will install talk, talk, vision, talk. Audio, copy, right click and hit answers. Meanwhile, this is installing. Let me show you the cigarettes that I have made. So for this, we will begin with cloning.
06:54
I will use test for folder to open any examination Cologne. Then cut the Donald secrets. Put them into the colonnade, main repository, which is audio craft. Paste them here. So you need to put these files into your colonel repository.
07:11
Into your cloud directory than just double click install, but file. It may ask you this, then just click run. Anyway, The bath file is very simple like this. You can also quote this if you wish, but you don’t have this bath pile, will install everything automatically for you if you don’t have a good GPU, don’t worry, there is a special Google Call up made for audio craft. I will also show you how to install and use audio craft on Google, Call up free account so we can continue our manual installation while our automatic installation is going on automatically.
07:46
After installing torque and torque, we just need to execute this command. I made this comment so easy for you. Just copy, paste and hit answer.
07:57
You see, as I do more research, more videos, I’m improving my skills and providing you better content so you don’t have to support me on Patreon. But if you support me on Patreon, I would appreciate it very much. We have our links in the top. You see, support me on Patreon, YouTube. You can also follow me on Twitter.
08:18
I am not a faceless person. I am Doctor Fouquet, and you can follow me. You can also connect me on my, I link it in as well. Also, don’t forget to join our Discord channel When you click this link, you will see our disclosure. You see, we have over 3000 members and we are growing. I am expecting you there as, okay, this step is also completed Now. We will install x forma. So copy paste. After you paste it, you need to hit enter. All right, now we are ready to start application, so I will close our manual installation and enter inside the folder. Open a new C, MD, then copy this comment and hit enter. And it will start a gradual interface.
09:03
Unfortunately, I couldn’t find a way to install Triton on Windows on the official repository of audio craft. I have opened several issue topics. You may see them here as well. I have asked, how can we install Triton, I have asked more information about top K, top P temperature and classifier pre guidance parameters. I also asked where we can get text token list. It was user to be trained on. So hopefully I will add more information to my read me file. So it started the URL. You need to copy this and open in your browser. So this is the inverter face that I have shown you in the beginning of the video.
09:47
Just type anything you want. For example, amazing grab song and select the model that you want to use. You can also use melody. And if you use melody, you need to drag and drop. And how the file here, So it will also use that condition.
10:03
There is also medium, small and large models, depending on your GPU viram, you can test them on artix. 3090. All of them works. And it is really fast.
10:13
So let’s generate this with large model. And I will keep video open while generating. So let me also show you the Vera usage. I also have several other applications open right now, so there is some extra little more Vram usage.
10:30
And video recording is also taking a lot of vitamin and GP power. However, it is working right now, as you are seeing. Moreover, when the first time you generate a song, it will download the models. Since I have downloaded already, it didn’t read a lot. But when the first time you generate. You will see Donald message like this, verge on the C, M. D. Window you launched at the usage. There is no messages because it is using the cashier with downloaded modern piles. I will also show you where these modeled piles are located.
11:06
Still generating our audio. It was like 6 seconds, So, and I am generating 30 seconds song. I try it to generate more than 30 seconds. However, it is not able to generate more than 30 seconds. Even if you wish. Okay, it took like 7 to seconds and you see, still I am recording. There are a lot of things going on right now. And it was really, really fast. Now, let’s listen it.
11:39
Okay, it looks like I didn’t even write the song properly. I have written some. So as you do more detailed input here, it will generate much better music. I will look for what kind of prompts we can do. So I’m not sure yet. This is like stable diffusion. You need to figure out proms. So let me show you where the model sales are saved. They are saved inside your sea, drive inside users inside your username in here, go to the cash folder in here, go to the hugging face in here, go to the hop and you will see models.
12:14
FaceBook, Music Chan. For example, large model, is taking 6 GB on my hard drive. Medium is taking 3 GB on my heart drive. 3.6, and melody model is 2.8. And small model is taking on the 1 GB on my heart, right, So for using condition, what you need to do is just click here, select the MPT file or another sound file and heat generate. Don’t forget to select model melody here. For example, let’s also try this with melody and let’s see how much time it will take. It says that it will take about 73 seconds, but I am not sure I can say that the FaceBook research is ahead of the other companies, such as Google.
13:00
Google announced music ML, but they didn’t release any models, anything to the public, so we couldn’t test them. We only saw their demos. However, in here.
13:11
We have something live that we can test. We can play with it. We can experiment with it. And this makes FaceBook much better in the AI realm. I hope I have pronounced it correctly in the AI realm. Yeah, and this is amazing.
13:29
I am following all of the AI needs, so keep subscriber to my channel, join our Discord. Hopefully if something new comes, I will make a video for it. I have a lot of backlog of new videos, knee tutorials. Even better, tourists will come, hopefully. Okay, it took 7 to 4 75. Yes, seventy-five, let’s listen.
14:21
I am pretty sure you will be able to compose much better music than, okay. Now, let me show you how to use these models, how to use audio craft on Google.
14:32
Call up for free. Just click the link I shared in this guitar REIT. My file, by the way, I have a guitar repository named a stable division. This is my main repository. Please start it for it. Watch it. I appreciated it helps me growing. I have many other tutorials and useful stuff here. Tricks here. I think you will like other content I share here as well. So I am open to Google, Call up. I will open in a knitted like this. This is our call. Up first, begin with connecting, click, connecting. It is connecting. This is a pretty simple secret. This secret made by Commandera. This guy is amazing. He is releasing how many Google collapse grips.
15:16
First, verify that you are connected to GPU. If you are not, change runtime from here, select GPU. If you are not able to select GPU, that means that your account is not verified. Phone number, very possibly, or you have used all of your GPU time, free time.
15:33
Then click play icon, run anyway, and just wait until it. Install everything and start the gradual link for us. Meanwhile, I will show you our automatic run cigarette that I have shared on the my Patreon post. It was already completed, the installation. You just double click the run that. Click more info. Click run. Anyway, this file is hundred percent safe because you can. And look what is inside. And it is justice. These are the just comments we executed. This script just automates it. And you see, you get your gradual link here.
16:10
Okay, our installation is going on on Google. Call up. You will also get this warning. Just ignore it. Don’t restart or don’t click this play icon again. You see, it has started gradual link, click it, and you will get a public gradual. This gradual is linked to this Google Call up runtime.
16:28
Let’s make a test with this one. So I click it. Let’s select a large model. I don’t know if large model may get out of Vita error on Google color. Please try it submit first. It will do not.
16:41
A large model on Google Call up. So this is running on cloud. Nothing here will affect your computer or will be downloaded onto your computer. Everything is, is Google servers. This is hundred percent safe. Let’s see. I wonder that if we will be able to use large model on Google, Call up free account. This is free account. Therefore, I have only 15 GB having GPR. Okay, so far we don’t have out of memory error. It is using 8 GB. I think it started processing.
17:12
We are waiting the results on Google Call up. It displays extra information like you are seeing right now. And we are at 11 GB GPU Ram. And we got a generated music, nice. Oh, very nice. Now let’s listen it.
17:59
Okay, for downloading the generated music files. You need to click this icon and it will download it onto your computer. By the way, on Google, Call up. It generated an MP4 file.
18:11
I will now try with a very long description prompt. Let’s see. Philip calls out of memory error or not, and how much time it will take, just. And let’s follow the GPU Ram usage. I wonder if the prompt length is affecting the user via memory amount. So you see, it is a huge problem. I generated it with Teddy P. T.
18:38
I am also monitoring the time it is going to take on my computer. It is usually taking about 60 seconds when the GPU. Is not much used. So on Google, Call up, we will see, by the way. On Windows, we weren’t fully utilizing the accelerators to a treat on library, which was missing on Windows. Google call up, It runs with eunuchs. Therefore, that is available, so it is more optimized than using this repository or window.
19:11
Okay, it was 90 seconds. 100 seconds, 120 seconds. Let’s look at the messages. 130, okay, about 130 seconds. The model was already loaded, so we didn’t wait or counted. Let’s listen.
19:57
Wow, this was epic. So you see. There is so much thing that you can do. I will test the same prompt on my computer to see whether there is any difference in generation time.
20:10
You see on Windows, we don’t have threatened. Therefore, some optimizations will not be enabled. But I think my GPU is still two times faster than what is on Google. Call up. So let’s open the interface type R text, large, modeled, select 30 seconds. By the way, if you use lesser duration, that may reduce your Vera usage. So let’s submit. Oh, first time it is loading the model. So I need to repeat the experimentation to ignore all the loading time. Meanwhile, I will also shut off my Google call up so it won’t use my GPU time. Just click here. Disconnect and delete. Run time, and it will delete everything and it will the Google collab.
20:52
Okay, 60 seconds. But it is also including the loading model time. Okay, it took like 96 seconds. Now I will submit again, by the way, each time you generate a new music. It will be different than previous one, depending on this top K top P temperatures and classifier free guidance variables. I ask them to the Chitty P T. And there are some information reading on this guitar video file that I will share in the video as a link in the description of the video and also in the comments section of the video. So you can read this and learn more about it. This is a general information based on the machine learning models. It is probably pretty accurate as well.
21:38
Okay, 40 seconds current. I am doing tests with only default parameters that the developers have said, but you can change them and see what kind of impact they are making. By the way, we are still recording video. Therefore, it is a little bit slower than what it should be around. 70 seconds in the right side, you. The last generation, it took to generate the music file. Okay, A D 5. Okay, looks like more prompt increases the time it takes to generate a song. Okay, yeah, it significantly increased at the time that it takes. And wow, this time it is taking even longer. It is maybe, probably because I am talking more. So, yeah. Okay, let’s listen this one.
22:55
I hope someone figures out, have to generate more than 30 seconds, because this, this is amazing. And for downloading, click these three icons and click on that. This is all for today. I hope you have enjoyed it.
23:06
Please support my Patreon. You can click here, you can connect with my link it in from here. You can follow me from Twitter from here. Please also subscribe. Leave a command shared, and please support me with joining on YouTube. I appreciate it very much. You will find the read the file link in the description of the video. Like here you see source GitHub file. This is from another view video about the same logic. And also in the Pinnacle command, you will also find the link of this Redmi.
23:35
File I shared. It is extremely important. I will keep it up to date, so if an error or something happens, I will write here based on your feedback.
23:45
If there are any other libraries that you need to install. I will write them here. Moreover, I have used Pip, please to list all of the installed libraries in my generated virtual environment. This is also logged, ridden in the very bottom of the rhythmical. So you can see all of the libraries with their versions. This is extremely useful because in future, when you watch this video, if you encounter a library error, you can see the version here and install a specific version. Now, for installing specific version, you need to use the following format, Peep installed, and the library that you want to install that equal, equal. And the version with this way, you can install the specific version of each library.
24:38
I hope you have enjoyed. Hopefully see you in another amazing tutorial.
我把视频内容翻译成如下:
00:00
大家好。FaceBook研究发布了一款名为Audio Craft的音乐生成器,它可以根据文本提示或给定的音频文件生成音乐。Audio Craft是迄今为止最好的音乐生成器。我将向大家展示如何安装和使用它。首先,我将向大家展示我在计算机上生成的一些示例。我在音乐方面并不擅长,所以可以认为这些是最差的生成样本。现在让我们一起来听一下。
01:02
为了生成这首歌曲,我使用了这个输入文本,并且没有使用任何中间条件。我使用了默认参数的大型模型,这个大型模型在RTX 3090上表现非常好。它可能需要大约15到16 GB的内存。但是,如果你的显存较低,也可以使用媒体模型或小型模型。
01:28
生成的音乐文件默认情况下不会保存在你的计算机上。所以你需要创建这个文件夹。点击这个图标,然后点击下载。它将把生成的音频文件保存到你的Domus boulders文件夹中。你可以自己决定如何获取你的输出。我没有太多机会进行测试,找到更好的例子。但是这个模型仍然很神奇。现在,在这个例子中,我将向大家展示将这个提示与模型自带的背景MP3文件相结合的情况。让我们来听一下生成的音乐。
02:39
我还使用了《Discretive comments》这首歌作为示例。让我也给大家展示一下它的声音,它很棒。首先,让我让你们听听旋律的编码。
03:07
现在让我们听一下结合了这个旋律编码和输入文本的生成音乐。
03:44
正如我所说的,这是一个随机挑选的例子。这是第一次生成,因为我没有太多时间进行测试和更多的实验。所以对于安装,我准备了一个很棒的GitHub Redmi文件。这个文件的链接将放在视频的描述中。随着需要,这个文件将得到更新,所以你可能会在这个文件中找到更多的信息。为什么我使用这样的文件?因为我正在制作很多人工智能内容,存储库一直在更新,而且很快就会发生故障。所以我会保持这个文件的更新,你们将能够始终关注这个视频并安装和使用这个开源库。
04:29
所以有两个要求你需要做。首先,你需要安装Python。我建议你使用Python 3
.x版本。我正在使用Python 3.10.9,并且它应该被设置为默认版本。所以当你在命令行窗口中键入python时,你应该看到像这样的消息。第二件你需要安装的是Git。当你在命令行窗口中键入git时,你应该看到类似于这样的git消息。如果你不知道如何安装它们,我有一个很好的教程视频。链接在这里,房顶链接在这里。
05:08
现在我将展示如何在你的计算机上安装Audio Craft。我还准备了一个自动安装和运行的批处理文件,它在我的Patreon帖子上分享。你可以下载这些批处理文件并直接使用它们。我也将展示如何使用它们。所以我们将进行比较。我已经将每个命令都放在这里,一个接一个地。所以如果你不想使用我的自动化批处理文件,很容易跟随。
05:34
首先进入你想要安装的文件夹内,我将创建一个名为test的文件夹,像这样。我已经进入了文件夹内。首先,我们将从这里开始克隆仓库。在这里打开一个新的命令行窗口。这是我的命令行窗口所在位置,右键点击并选择克隆。然后进入克隆的文件夹,复制它,粘贴并移动到文件夹内。然后,如果你想使用我在这个视频中使用的相同版本,执行git checkout。只有在遇到问题并且它不起作用时才这样做。否则,你不需要这样做。你应该使用仓库的最新版本,因为开发人员通常修复错误并添加新功能。然后我们将生成我们自己的虚拟环境。这一步非常重要,因为通过这种方式,它不会与其他安装发生冲突,比如稳定版本。复制,粘贴。然后输入activate,然后我们将安装torchaudio。复制,右键粘贴,然后按回车。在安装过程中,让我给大家展示我制作的批处理文件。所以,我们将从克隆开始。
06:54
我将使用test文件夹打开任何一个命令行窗口,然后复制下载的批处理文件。将它们放入Audio Craft的主要仓库,即colonnade。将它们粘贴到这里。所以你需要把这些文件放到你的colonnade仓库中。
07:11
放入你的colonnade仓库的云目录中,然后双击install.bat文件。它可能会询问你这个问题,然后点击运行。无论如
何,这个批处理文件非常简单,像这样。如果你愿意,你也可以引用它,但是如果你没有这个批处理文件,它会自动为你安装所有内容。如果你没有一块好的GPU,不用担心,audio craft有一个专门为Google Colab制作的版本。我也将向你展示如何在Google Colab免费账户上安装和使用audio craft,所以在我们的手动安装正在自动进行的同时,我们可以继续我们的手动安装。
07:46
在安装了torchaudio之后,我们只需要执行这个命令。我为你制作了这个命令非常简单。只需复制,粘贴,然后按回车。
07:57
你看,随着我进行更多的研究、制作更多的视频,我不断提高我的技能,为你提供更好的内容,所以你不必在Patreon上支持我。但如果你在Patreon上支持我,我会非常感激。你可以在顶部看到我们的链接,支持我在Patreon上,YouTube上。你也可以关注我的Twitter。
08:18
我不是一个没有面孔的人。我是Fouquet博士,你可以关注我。你也可以在我的ilinkedin上联系我。同时,不要忘记加入我们的Discord频道。当你点击这个链接时,你会看到我们的介绍。你可以看到,我们有超过3000名成员,而且我们还在不断增长。我期待着你的加入,好吗?这一步也完成了。现在,我们将安装x forma。复制,粘贴。粘贴之后,你需要按回车。好的,现在我们准备开始应用程序了,所以我将关闭我们的手动安装,进入文件夹内。打开一个新的命令行窗口,然后复制这个命令并按回车。它将启动一个图形界面。
09:03
不幸的是,我找不到在Windows上安装Triton的方法,它在audio craft的官方仓库中。我已经提出了几个问题。你也可以在这里看到它们。我问了,我们如何安装Triton,我问了更多关于top K、top P、temperature和classifier pre guidance参数的信息。我还问了我们在哪里可以获得文本token列表。它曾经是用来训练的。所以希望我能在我的readme文件中添加更多信息。它启动了一个URL。你需要复制这个URL并在浏览器中打开。这就是我在视频开头给大家展示的界面。
09:47
只需输入你想要的任何内容。例如,amazing grab song,并选择你想要使用的模型。你还可以使用melody clip,它是模型自带的一个背景音乐。如果你不想使用它,你可以将它设置为none。我将展示一些例子。所以你可以看到,我将曲目名称设置为song1,并选择了大型模型。然后你只需按Generate按钮。然后你需要等待一段时间,它将生成你的音频文件。这是整个安装和使用过程。我希望你们喜欢这个视频,也希望你们能在评论中告诉我你们的想法和意见。谢谢大家!
10:03
根据你的GPU显存,还可以在Artix.3090上测试它们。所有模型都可以工作。而且速度非常快。
10:13
所以我们使用大型模型来生成。在生成过程中,我会保持视频开启。让我也向你展示一下Vram的使用情况。我现在还有几个其他应用程序在运行,所以额外使用了一些Vram。
10:30
同时,视频录制也占用了很多显存和GPU的资源。然而,正如你所看到的,它目前正在工作。此外,当你第一次生成一首歌曲时,它会下载模型。由于我已经下载过了,所以它没有读取很多。但是当你第一次生成时,你会看到像这样的提示消息,说明它正在使用你在启动CMD窗口时所看到的Vram使用情况。由于它正在使用缓存和已下载的模型文件,所以没有提示消息。我还会向你展示这些模型文件存储的位置。
11:06
仍在生成我们的音频。大约花了6秒钟,我要生成30秒的歌曲。我尝试生成超过30秒的,但是它不能生成超过30秒的歌曲,即使你希望。好的,花了大约7到秒钟,你看到我仍在录制。现在正在进行很多事情,而且速度非常快。现在,让我们来听听它。
11:39
好吧,看起来我甚至没有正确地编写歌曲。我写了一些。所以你在这里提供更详细的输入,它将生成更好的音乐。我会寻找可以使用的提示。所以我还不确定。这就像是稳定扩散。你需要找出提示。让我向你展示模型文件的保存位置。它们保存在你的C驱动器内,用户文件夹下的用户名文件夹内,进入缓存文件夹,然后进入hugging face文件夹,你会看到模型文件。
12:14
例如,Facebook音乐频道。例如,大型模型在我的硬盘上占用了6GB。中型模型在我的硬盘上占用了3GB。3.6,旋律模型占用了2.8。小型模型在我的硬盘上占用了1GB。因此,要使用条件,你只需在这里点击,选择MPT文件或其他音频文件,然后点击生成。不要忘记在这里选择旋律模型。例如,让我们也尝试使用旋律模型,看看需要多长时间。它说需要大约73秒,但我不确定能否说Facebook研究在人工智能领域领先于其他公司,如Google。
13:00
Google宣布了音乐ML,但他们没有发布任何模型或对公众开放,所以我们无法测试它们。我们只看到了他们的演示。然而,在这里,我们有一个可以测试的实时工具。我们可以使用它进行实验。这使得Facebook在人工智能领域更加出色。我希望我在AI领域的发音是正确的。是的,这太神奇了。
13:29
我正在关注所有的AI需求,所以请订阅我的频道,加入我们的Discord。希望如果有新的东西出现,我会为它制作视频。我有很多新视频,新教程的积压。甚至会有更好的教程出现,希望如此。好的,花了7到75秒,让我们听一下。
14:21
我相信你们一定能创作出比这个更好的音乐,好的。现在,让我向你展示如何在Google上使用这些模型,如何使用AudioCraft。
14:32
免费下载。只需点击我在这个帖子中分享的链接。顺便说一下,我有一个名为”stable division”的吉他存储库。这是我的主要存储库。请收藏它,观看它。我感激不尽,它有助于我的成长。我这里还有许多其他教程和有用的内容。在这里分享的其他内容也会让你喜欢。所以我正在打开Google Call Up。我会像这样打开。这是我们的Call Up。首先,连接起来,点击连接。正在连接。这是一个非常简单的密码。这个密码是由Commandera创建的。这家伙很厉害。他发布了多少Google Collapse脚本。
15:16
首先,验证你是否连接到了GPU。如果没有连接到GPU,从这里更改运行时,选择GPU。如果无法选择GPU,那么可能是你的帐号没有验证。很可能是手机号码的问题,或者你已经用完了所有的GPU免费时间。
15:33
然后点击播放图标,无论如何运行,然后只需等待。安装和启动渐进式链接。与此同时,我将向你展示我在我的Patreon帖子上分享的自动运行脚本。它已经完成安装。你只需双击运行它。点击更多信息。点击运行。无论如何,这个文件是百分之百安全的,因为你可以查看其中的内容。而且它是正当的。这些只是我们执行的一些命令。这个脚本只是自动化了这些过程。你看,你在这里获得你的
渐进链接。
16:10
好的,我们在Google Call Up上进行安装。你也会收到这个警告。只需忽略它。不要重新启动,也不要再次点击播放图标。你会看到它已经启动了渐进链接,点击它,你将获得一个公共的渐进链接。这个渐进链接与你的Google Call Up运行时相关联。
16:28
让我们用这个进行测试。所以我点击它。让我们选择一个大模型。我不知道大模型是否会在Google Call Up上出现内存错误。请先尝试提交。不会出错的。
16:41
在Google Call Up上的大模型。所以这是在云端运行的。这里的一切都不会影响你的计算机,也不会下载到你的计算机上。一切都是在Google的服务器上。这是百分之百安全的。让我们看看。我想知道我们是否能在Google Call Up的免费帐户上使用大模型。这是免费帐户。因此,我只有15GB的GPU内存。到目前为止,我们还没有遇到内存不足的错误。它正在使用8GB。我想它已经开始处理了。
17:12
我们正在等待Google Call Up的结果。它会显示额外的信息,就像你现在看到的一样。我们的GPU内存使用量为11GB。我们得到了一段生成的音乐,很棒。哦,非常好。现在让我们来听听它。
17:59
好的,要下载生成的音乐文件,你需要点击这个图标,它会下载到你的计算机上。顺便说一下,在Google Call Up上,它生成了一个MP4文件。
18:11
我现在将尝试一个非常长的描述提示。让我们看看,是否会出现内存错误,以及需要多长时间。同时让我们关注GPU内存的使用情况。我想知道提示长度是否会影响内存的使用量。你看,这是一个巨大的问题。我用Teddy P.T.生成了它。
18:38
我也在监控它在我的计算机上需要多长时间。当GPU没有被大量使用时,通常需要大约60秒钟。所以在Google Call Up上,我们将看到,顺便说一下,在Windows上,我们没有完全利用加速器对待库的优势,这在Windows上是缺失的。Google Call Up使用的是Unix。因此,它更加优化,而不是使用这个存储库或Windows。
19:11
好的,用了90秒。100秒,120秒。让我们看一下消息。130秒,好的,大约130秒。模型已经加载完毕,所以我们没有等待或计算加载时间。让我们来听听。
19:57
哇,这太棒了。你看,你可以做很多事情。我将在我的计算机上测试相同的提示,看看生成时间是否有任何不同。
20:10
你看,在Windows上,我们没有threatened库。因此,某些优化将无法启用。但我认为我的GPU速度仍然比Google Call Up上的速度快两倍。所以让我们
打开界面,输入文本,选择大型模型,设置为30秒。顺便说一下,如果你使用更短的时长,可能会减少你的计算资源使用量。然后点击提交。哦,第一次加载模型。所以我需要重复实验,忽略所有的加载时间。与此同时,我也会关闭我的Google Call Up,这样它就不会占用我的GPU时间。只需点击这里。断开连接并删除运行时,它将删除一切并关闭Google Collab。
20:52
好的,60秒。但这也包括加载模型的时间。好的,花了大约96秒。现在我会再次提交,顺便说一下,每次生成新音乐时,都会与之前的不同,这取决于top K、top P和温度以及分类器的自由度变量。我向Teddy P.T.询问了这些。还有一些关于这个吉他视频文件的信息,我会在视频的描述中分享一个链接,并在视频的评论部分中分享。所以你可以阅读它并了解更多信息。这是基于机器学习模型的一般信息。它可能也是相当准确的。
21:38
好的,当前为40秒。我正在进行只使用开发人员所说的默认参数的测试,但你可以进行更改,看看它们产生的影响。顺便说一下,我们仍然在录制视频。因此,速度比预期要慢一些。右侧显示的是上一次生成音乐文件所用的时间。好的,AD5。看起来,更长的提示会增加生成所需的时间。好的,是的,它显著增加了所需的时间。哇,这一次花的时间更长。可能是因为我说话更多了。所以,是的。让我们听听这个。
22:55
我希望有人能弄清楚如何生成超过30秒的音乐,因为这太棒了。要下载,请点击这三个图标,然后点击其中一个。今天就到这里吧。希望你们喜欢。
23:06
请支持我的Patreon。你可以点击这里,也可以从这里连接到我的LinkedIn。你可以从这里关注我的Twitter。还请订阅、留言和支持我加入YouTube。非常感谢。你将在视频描述中找到阅读文件的链接,就像这里所示,你可以看到源GitHub文件。这是关于相同逻辑的另一个视频。还有在Pinnacle command中,你还会找到这个Redmi文件的链接。
23:35
我分享的文件非常重要。我会不断更新它,所以如果发生错误或其他情况,我会根据你的反馈在这里写下来。
23:45
如果有其他需要
安装的库,我会在这里写下来。此外,我已经使用Pip列出了我在生成的虚拟环境中安装的所有库。这也被记录在Rhythmical的最底部。因此,你可以看到所有库及其版本。这非常有用,因为在将来,当你观看这个视频时,如果遇到库错误,你可以在这里看到版本并安装特定的版本。现在,要安装特定的版本,你需要使用以下格式:Peep installed,然后是你想安装的库的名称,等于号,等于号,以及版本号。这样,你就可以安装每个库的特定版本。
24:38
希望你们喜欢。希望能在另一个令人惊叹的教程中见到你们。

